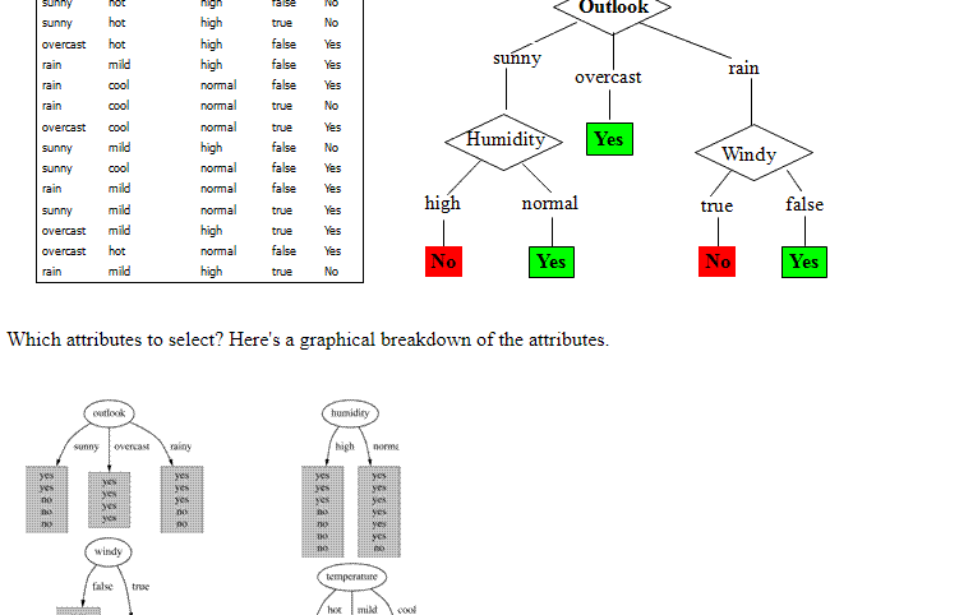
Decision trees, and data mining are useful techniques these days.A decision tree is a hierarchical relationship diagram that is used to determine the answer to an overall question. It does this by asking a sequence of sub-questions related to that question. Each ...
OurPcGeek Latest Articles
What is Data Mining?
OurPcGeek
Data Mining is the process of identifying trends in large data sets. Steps are as following: Business understanding Data understanding Data preparation Modeling Evaluation Deployment The data is usually collected and stored in data warehouses. Then we apply suitable data ...
Highlighting what’s important about questions & Answers on Discy Community!
Ahmed Hassan
We want to make it easier to learn more about a question and highlight key facts about it — such as how popular the question is, how many people are interested in it, and who the audience is. To accomplish ...
Organizational and company accounts on Discy Engine the next step
Ahmed Hassan
We want to make it easier to learn more about a question and highlight key facts about it — such as how popular the question is, how many people are interested in it, and who the audience is. To accomplish ...
Defining quality on Discy Engine — what a helpful answer looks like?
Ahmed Hassan
We want to make it easier to learn more about a question and highlight key facts about it — such as how popular the question is, how many people are interested in it, and who the audience is. To accomplish ...
Introducing Keyboard Shortcuts, our first Labs feature
Ahmed Hassan
We want to make it easier to learn more about a question and highlight key facts about it — such as how popular the question is, how many people are interested in it, and who the audience is. To accomplish ...
Highlighting what’s important about questions & Answers on Discy Community!
Ahmed Hassan
We want to make it easier to learn more about a question and highlight key facts about it — such as how popular the question is, how many people are interested in it, and who the audience is. To accomplish ...